Python Tutorial: Short Stop To Introduce Main Statistical Concepts
Explaining the concepts by using our tutorial program as a showcase
I planned to introduce in this session the merging algorithm for our two data sets via the name variables.
To outline the overall approach understandably and concisely, it’s essential to bring some statistical concepts beforehand.
I decided to do a short bus stop and embed the work into the statistical framework, which underlies any data exploration project. So no programming today just some concepts, which are vital for the overall understanding. I plan more statistics bus stops in the future to get the scientific context of our program established.

Photo by chuttersnap on Unsplash
Population, Sample, Measurement, Parameter, and Statistic
We begin with some basic definitions used in statistics, by using the
introduction tutorial
of the Saylor Academy (the content is provided under a
creative commons license
)
PopulationA population is any specific collection of objects of interest. A sample is any subset or subcollection of the population, including the case that the sample consists of the whole population, which maps to the term census.
In our case, the population is the Swiss government members (councilors) of the
Federal Assembly of Switzerland
.

Sample
Our sample is all councilors, which have a Twitter account and listed as a member of the
SoMePolis Twitter Parliament List
. It’s a subset, so we don’t use the term census for the population.
MeasurementA measurement is a number or attribute/variable computed for each member of a population or sample. The measurements of sample elements are collectively called the sample data.
For each member of the sample set, we are collecting variables via two data set’s i.e., the first set of variables are collected via the Twitter API, the second set via the Government API.
Sample Data
Our overall sample data set we get by unifying these two data sets.
A parameter is a number that summarizes some aspect of the population as a whole. A statistic is a number computed from the sample data.
Because our numbers to be computed are based on a subset of a population, we talk about a statistic and not a parameter.
That’s it about the initial scope definition, let’s focus now about the “Variables” concept which is crucial.
Data Set’s and Variables
As a fresh up, let’s look at the two data sets, which we retrieved already:
As a first table (
Tutorial 2
), we retrieved from Twitter the following data record of Swiss politician Twitter accounts.
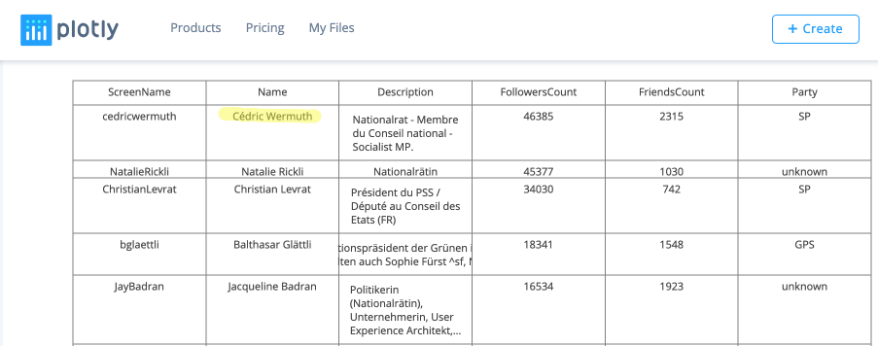
It provides us with three statistical variables playing a role in our future analysis:
-
FollowersCount
-
FriendsCount
-
Party
-
Name, which may represent the Twitter users real name. The word “may” is here essential, but more to that later.
What we also got from Twitter is an
Identifier
variable, which helps us reveal the real identity of a person (in our case a member of the Swiss council):
-
ScreenName which is the unique identifier of a Twitter account. We can use it in the case have to retrieve additional information via the Twitter API in a later stage.
As a second Table (
Tutorial 3
), we retrieved via the Swiss Government API the list of all current councilors of the
Federal Assembly of Switzerland
.
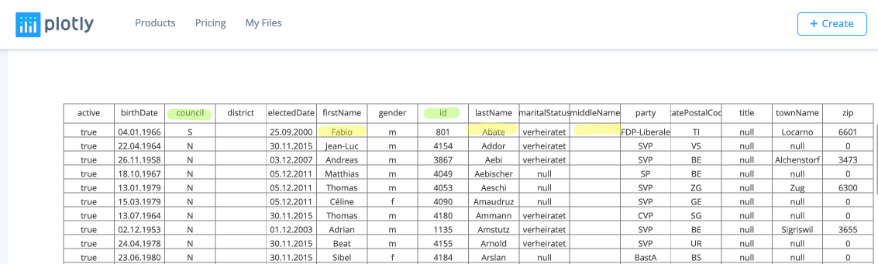
From this table, we got the following variables, which we want to use for our statistical assessment:
-
firstName-middleName-lastName, which is the (council’s) person name.
-
birthDate
-
council, the assembly is made up of two chambers i.e., the National Council (lower house) and the Council of States. Which is represented by the value ’N’ or ‘S’ in the table.
-
electedDate
-
gender
-
maritalStatus
-
party
-
home address (postal Code, townName, zip)
As well as the Identifier Variable
-
id, which identifies the data record in the context of the government API
Let’s dig a little bit deeper about the statistical meaning of variables used in our data sets
Variable Term Definition
In statistics, a variable has two defining characteristics. (1) A variable is an attribute that describes a person, place, thing, or idea. (2) The value of the variable can “vary” from one entity to another.
In our example, a person’s
gender
,
political party
or T
witter follower count
are potential variables.
Data type categorization
The Data Type of a variable plays an important role in statistics which must be understood, to correctly apply statistical measurements to your data. In statistics, the term “Measurement Scale” may be used as well.
The following tree categorizes the data type concept
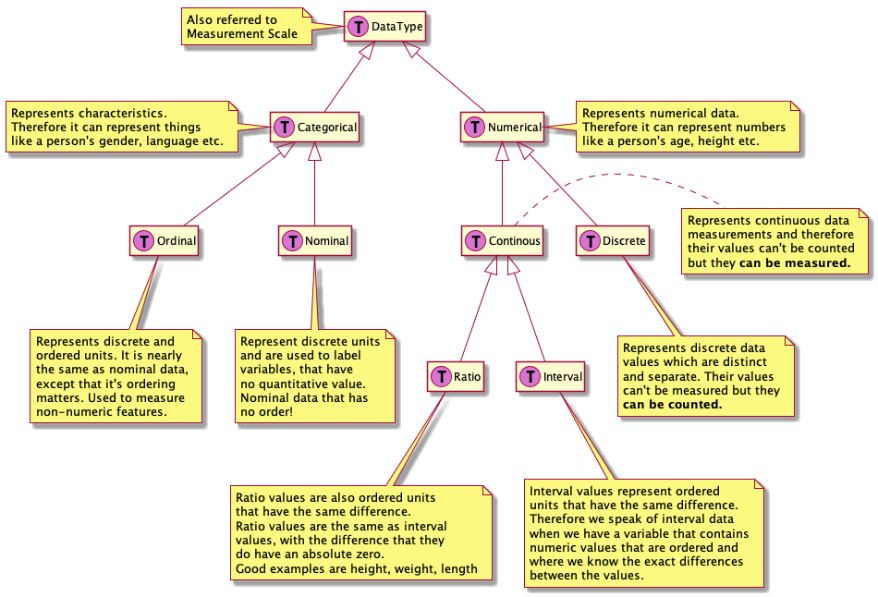
Refer to the following excellent
Medium article
to get an overall introduction to the data type topic.
Let’s apply the classification to our two data sets, which results in the following table.
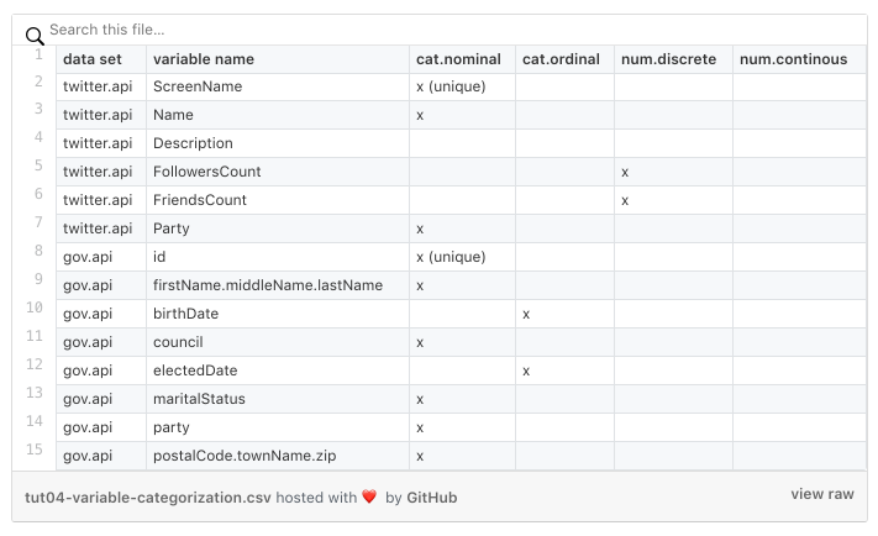
Two comments
-
We marked for each set a variable as “unique” which is identifying a dedicated sample result and on which we cannot perform any data analysis. A so-called Identifier Variables
-
In the gov.api data set, I bundled some variables together for describing a person or address. I.e., the name of a person is made of firstName, middleName, and lastName of a home address of person consisting of postalCode, townName, and zip.
A multitude of variable types exists, which can be classified with the above scheme (refer to the reference sections for additional links), but we are interested now in the so-called Identifier Variables.
Identifier Variables
Identifier Variables and Unique Identifiers are commonly used in statistics to unique identifies for data collection purposes.
Identifier variables are categorical variables that have a single individual per category. For example:
A Social Security Number, Interviewer ID number or Employee ID number.
As identifier variables are singular, it’s impossible to perform any data analysis on them. Instead, they are used to identify results.
Well, our two data sets have a unique identifier in the own domain, but there is no real unique identifier which allows combining the two data-set directly via a unique identifier which is available in both (cross-domain) data set.
In an ideal world, both records would have a unique identifier i.e., a national identifier in their data sets which allows to merge them easily.
The below example shows the national identity card of Switzerland, which has a unique identity number for Swiss citizen (holding an identity card).

Swiss ID Card —
Source
The below identifier requires that a person holds an identity card, in case a person holds just a passport, you would have to get the unique passport identifier. People who are not traveling wouldn’t have potentially any of the two identity means.
An even better identifier would be a national security identifier, which almost every citizen holds (after a certain age). Below the number for a person domiciled in Switzerland.

Swiss Social Security Number —
Source
The reality is that your public acquired data sets will not include such
highly sensitive
numbers of persons.
Such strong identification numbers should never be exposed in an unsecured manner (sharing the public on the Internet). Refer to the following article by CNN which describes one of the famous data hacks of Equifax, which resulted in the leaking of the social security number of 143 million Americans.
Criminals can use your Social Security number to steal your identity. They can open bank accounts and credit cards or apply for a loan. Hackers can also get ahold of your tax refund or get medical treatment under your name. ( money.cnn.com)
That concludes our introduction to statistical concepts for today and brings us back in the next article, to solving the problem via Python of joining data sets which don’t have a universal unique identifier.
In our case we have in both data sets one (or multiple) attributes which describes the personal name of a person. However, be aware;
When names are your only unifying data point, correctly matching similar names takes on greater importance. However, their variability and complexity make name matching a uniquely challenging task. Nicknames, translation errors, multiple spellings of the same name, and more all can result in missed matches. ( rosette.com)
That’s exactly the situation we are confronted now, let’s move on in the next article.
References
-
A comprehensive list of different variable types (well any type you can imagine) — Link: datasciencecentral.com
This blog entry was fully produced within Evernote and published using the
Cloudburo Publishing Bot
.
comments powered by Disqus