Personal Data API Part 1
The goal of this blog series is to position and define a data API for handling Personal Data which can be amongst other used by Financial Institutes to manage this information asset - which is also called the the oil of the information age - in a diligent and secure way.
In the current blog (first part) the major concepts and terms around Personal Data are introduced.
The findings are based on my work as a responsible architect for a major program within a large Swiss Bank, where we introduced a private data architecture to mitigate and reduce the operational risk of data leakage which could result in a major reputational damage.
Why Personal Data matters
It’s important to realize that a careful and correct management and provisioning of Personal Data provides huge opportunities.
As the first-phase World Economic Forum report on personal data elaborated, personal data represents an emerging asset class, potentially every bit as valuable as other assets such as traded goods, gold or oil.
As an emerging asset class, personal data currently lacks the rules, norms and frameworks that exist for other assets. The lack of trading rules and policy frameworks for its movement have resulted in a deficit of trust among all stakeholders and could undermine the long-term potential value of personal data. Different jurisdictions are looking to tackle this deficit of trust through different approaches, ranging from fundamental rights-based approaches to harm-minimization approaches.
(via World Economic Forum report on personal data)
- By addressing the client data confidentiality problem in your organization you will be capable to manage reputational risk diligently, but
- There is also the chance to build the foundation for a personal data management solution which would allow a financial institution to exploit new personal data driven business models with a potential high value proposition.
Definition of Personal Data
For a start we define the term Personal Data, by using the defintion of the Liberty Guide of Human Rights
Personal data is anything which identifies you as an individual, either on its own or by reference to other information. It can include expressions of opinion about you.
(via Your rights - Definition of Personal Data)
This general definition is a base for the various country specific data protection acts (DPA) which can and will vary in the interpretation of the term and it’s derived local laws and regulations.
As an example refer to the DPA of Switzerland which attaches a great deal of importance to protecting personal data, defines the Term, as follows
The Swiss Federal Data Protection Act (DPA) defines personal data as “all information relating to an identified or identifiable person”.
“Person” refers not only to a natural person (individual), but also to a legal entity. The legal form of the entity is not relevant. Accordingly, personal data under the DPA can mean data relating to individuals as well as to partnerships, corporations, associations, cooperatives or any other legal entity. The extension of protection for data relating to legal entities can create difficulties in the context of cross-border data transfers because few other countries provide adequate protection for data relating to legal entities.
A person is “identified” or “identifiable” if the information permits the identification of the person concerned. A person can be identifiable even if the data are stored in an anonymous form, e.g., under a code number, but separate information allows a link to be made between the code and the identity of the person. A person will be deemed not to be identifiable only if the information is anonymous and no link can be established between the anonymous information and the person concerned.
(via dataprotection.ch - Walder Wyss Ltd.)
So the term individual (representing a natural person) is expanded to legal entities as well in this definition. Important point in this context is the topic about cross border data transfers due to the fact that other countries may have more relaxed DPA’s concerning legal entities. This fact has to be taken in consideration as well when defining such a data API.
Two other terms are important in this context the first one, is Sensitive Personal Data, which is defined in the Swiss DPA as follows
- religious, philosophical, political or trade union-related views or activities
- health, the intimate sphere of the person or racial origin;
- social assistance measures; or
- criminal or administrative proceedings and penalties.
The other one Financial Personal Data which may or may not be part of Country’s DPA. For Switzerland the following applies
Financial data are not sensitive personal data under the DPA. Switzerland’s banking secrecy law, however, protects the confidentiality of the existence of the banking relationship, the identity of the bank’s customer and any other information related to the banking relationship.
(via dataprotection.ch - Walder Wyss Ltd.)
In our definition (aiming at Financial Services) we will include this kind of Personal Data as well.
That’s it from a definition point of view concerning Personal Data, let’s look at two additional highly important concepts which are closely related.
Anonymous and Anonymized Data
When we store Personal Data we normally will also include additional Anonymous Data of the person which are relevant for our processing systems but which never can be linked back to Personal Data, which would break secrecy, e.g. we want to store
- the customer segment of a person,
- his classification in context of regulatory obligation (e.g. a Fatca status)
- or any kind of information which is relevant for our business.
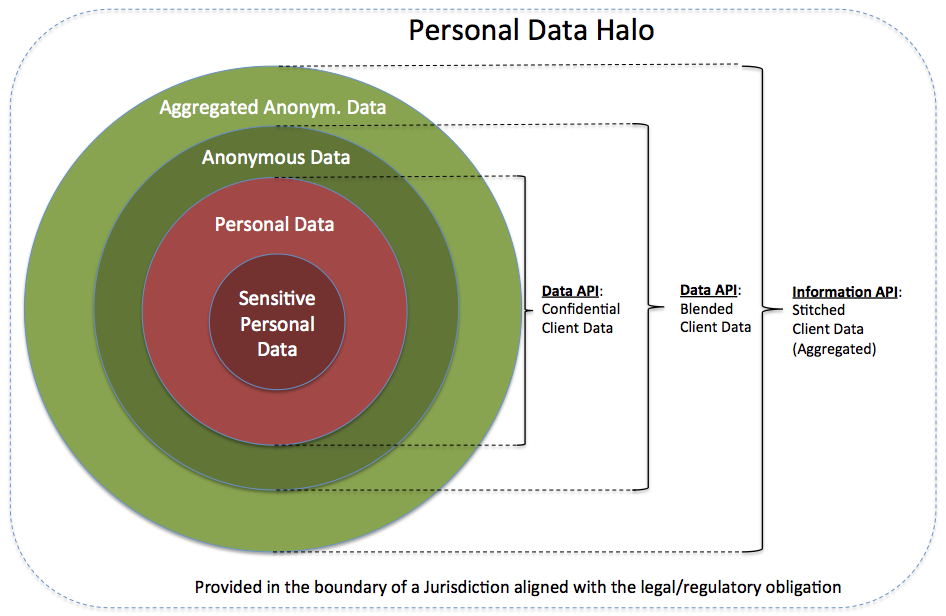
In context of our API discussion we call it also *Blended Data *, i.e. our Personal Data is blended with Anonymous Data in order that it can be processed and used by other IT systems. Blended Data is about data which is in direct relationship with the Person, normally known as data out of the domain of Client Relationship Management.
On top of that we have Aggregated Data which we also call Stitched Data, i.e. the blended data set of a person will be extended with additional data ( stitched together) out of another domain (risk domain) in order to do some domain specific analytics or calculation (risk exposure calculations)
In case we have Personal Data which have be deidentified, we are using the term Anonymized Data
Previously identifiable data that have been deidentified and for which a code or other link no longer exists. A provider, third party or investigator would not be able to link anonymized information back to a specific individual.
(via Managed Care and Healthcare Terminology)
It’s worth to mention that Anonymous Data is often defined as data without any identifier, meaning there is now way back to the Personal Data (e.g. doing a survey with questionnaires not noting down any personal data). In our discussion the Anonymous Data will have a link back to the personal data via an Internal Processing Identifier (IPID). This identifer can be used to resolve back to the personal data only by dedicated master systems which are runnig under the jurisidicational legal and regulatory obligations and are protected by the highest security standards in order to ensure privacy. This holds true for the Anonymized Data as well, there is a link back but third party or investigator only have a key which isn’t resolveable in any circumstance.
The Personal Data Halo
Inspired by the presentation of Sam Ramji from apigee Amundsen’s Dogs, Information Halos and APIs: The epic story of your API Strategy I will call the bundling of this various concepts into set of API as the Personal Data Halo.